/概念/
Hash
一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值
基本特性
根据同一散列函数计算出的散列值如果不同,那么输入值肯定也不同。但是,根据同一散列函数计算出的散列值如果相同,输入值不一定相同
碰撞
两个不同的输入值,根据同一散列函数计算出的散列值相同的现象叫做碰撞
常见的解决碰撞的方法有以下几种:
- 开放定址法
- 链地址法
- 再哈希法
- 建立公共溢出区
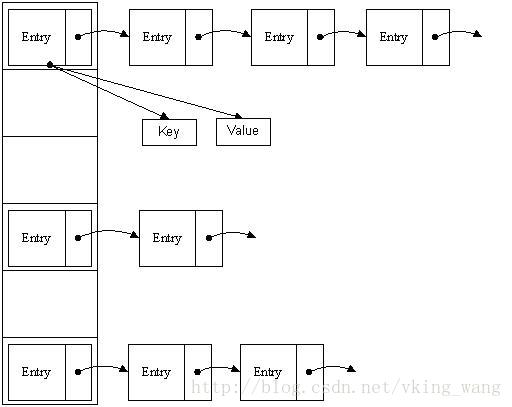
HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,hash
HashMap的数据结构
数组和链表。数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易
HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,hash
/哈希函数/
HashMap 哈希函数步骤
- 对key对象的hashCode进行哈希扰动
- 然后用位运算代替取模求出数组下标
扰动是为了让hashcode的随机性更高,第二步取模就不会让所以的key都聚集在一起,提高散列均匀度。扰动可以看到hash()方法:
获取数组下标
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
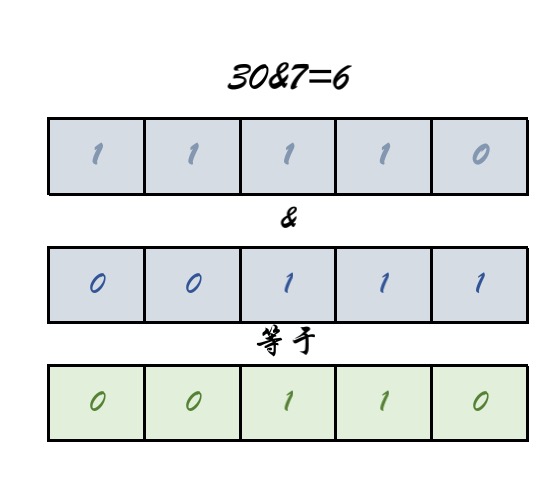
问题1:取模运算不是应该 hash%length???为什么是(length-1)&hash 🙄
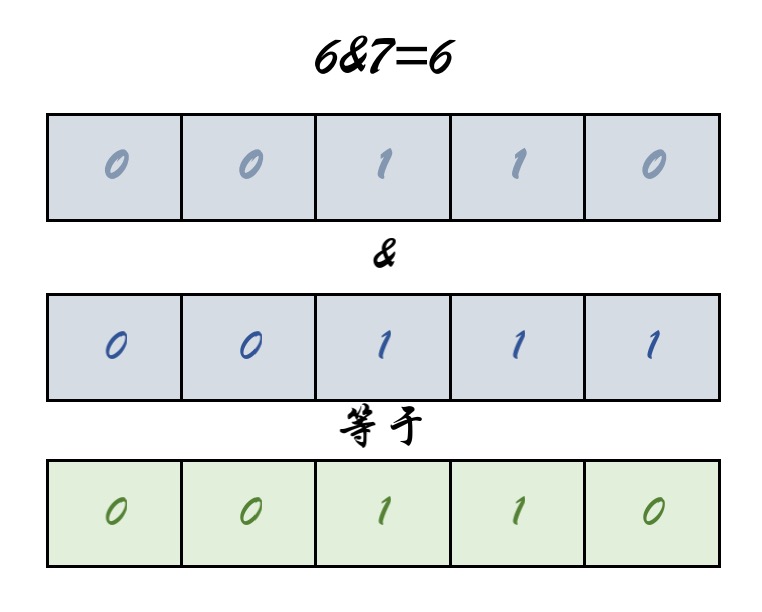
总结:为了考虑性能,Java总采用按位与操作实现取模操作 h & (length-1)= hash%length
问题二:这样位运算碰撞的几率是不是很高??
2:哈希扰动(jdk 1.8)
1 | static final int hash(Object key) { |
总结:就是低16位是和高16位进行异或,一般的数组长度都会比较短,取模运算中只有低位参与散列;高位与低位进行异或,让高位也得以参与散列运算,使得散列更加均匀
如下图
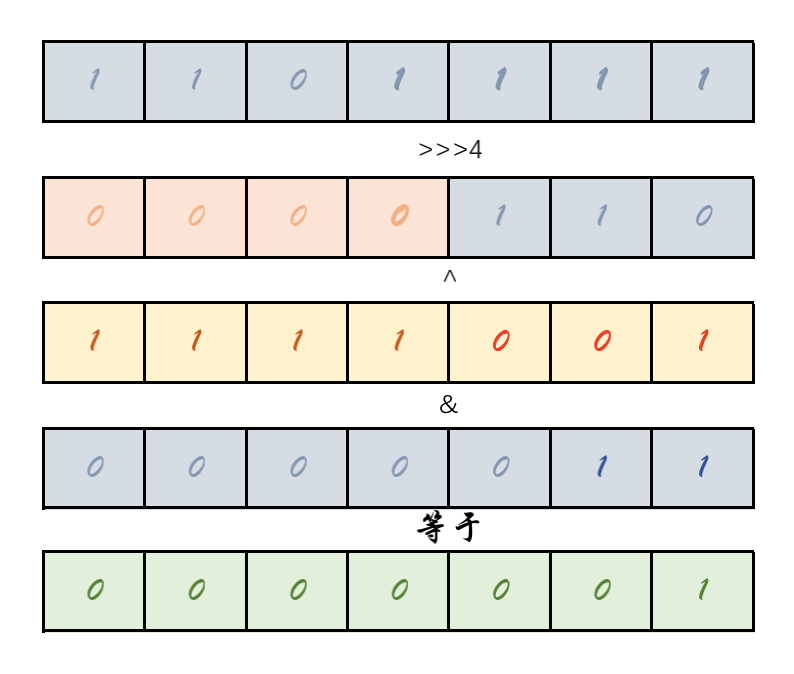
总结:
- 有效避免冲突措施是16位低位和16位高位进行异或,使得散列更加均匀
- 取数组下标:位运算代替模运算,使得计算效率更加高效。也是为什么2的倍数的其中一点原因
/哈希冲突/
再优秀的哈希算法都永远解决不了冲突,也就是不同key经过hash计算之后得到数组下标相同。HashMap采用的是链地址法,JDK1.8增加了红黑树。当链表过长之后,会自动转化成红黑树提高查找效率。红黑树是一个查找效率很高的数据结构,时间复杂度为O(logN),但红黑树只有在数据量较大时才能发挥它的优势。
转红黑树的限制
- 当链表≥8且数组长度≥64时候才会转化为红黑树
- 当链表长度≥8但是数组长度**<64**那么是优先扩容,而不是转为红黑树
- 当红黑树节点小于≤6,会自动转化链表
为什么数组≥64的条件才会转化红黑树?
当数组长度16时候,链表长度≥8时候,至少是占用了最大限度的50%,意味着负载已经快要达到上限,此时如果转化成红黑树,之后的扩容又会再一次把红黑树拆分平均到新的数组中,这样非但没有带来性能的好处,反而会降低性能。所以优先考虑扩容
为什么链表≥8才会转化为红黑树?
树节点的比普通节点更大,在链表较短时红黑树并未能明显体现性能优势,反而会浪费空间,在链表较短是采用链表而不是红黑树。出现链表长度到达8的概率很低。所以正常情况夏链表是更加合适的。
/扩容方案/
装载因子=HashMap中节点数/数组长度
JDK1.7 VS JDK 1.8
1.7之前的数据迁移比较简单,就是遍历所有的节点,把所有的节点依次通过hash函数计算新的下标,再插入到新数组的链表中。会产生一下缺点:
- 每个节点都需要进行一次求余计算;
- 插入到新的数组时候采用的是头插入法,在多线程环境下会形成链表环
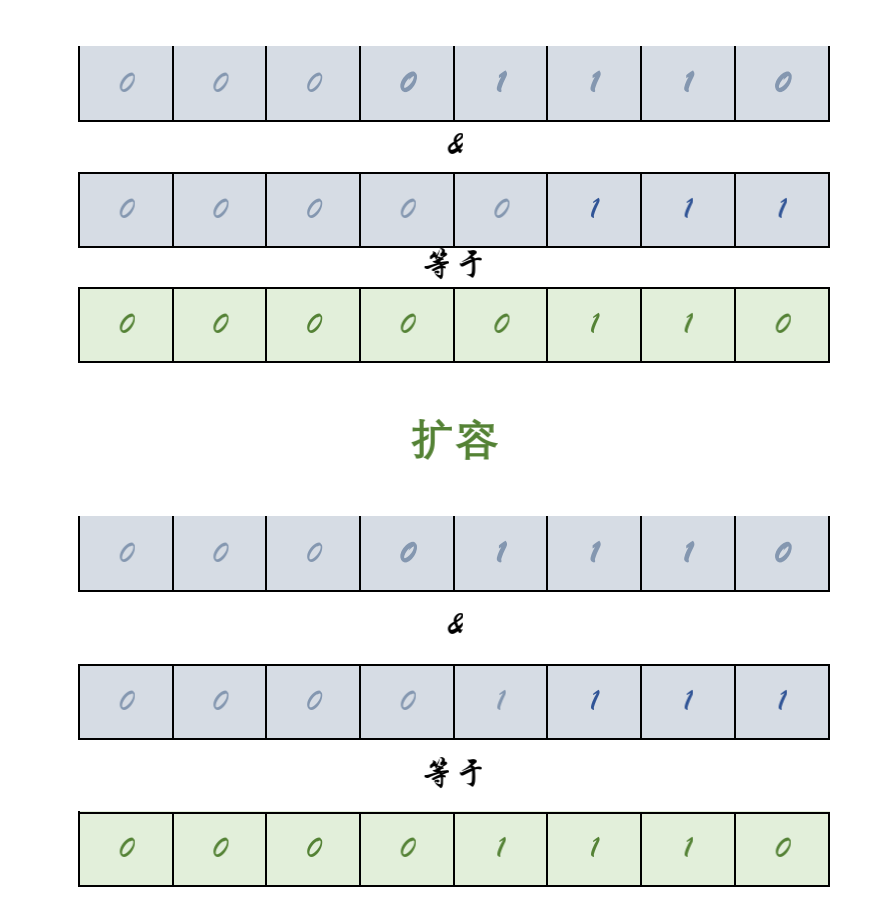
jdk1.8之后进行了优化,原因在于他控制数组的长度始终是2的整数次幂,每次扩展数组都是原来的2倍,带来的好处是key在新的数组的hash结果只有两种:在原来的位置,或者在原来位置+原数组长度
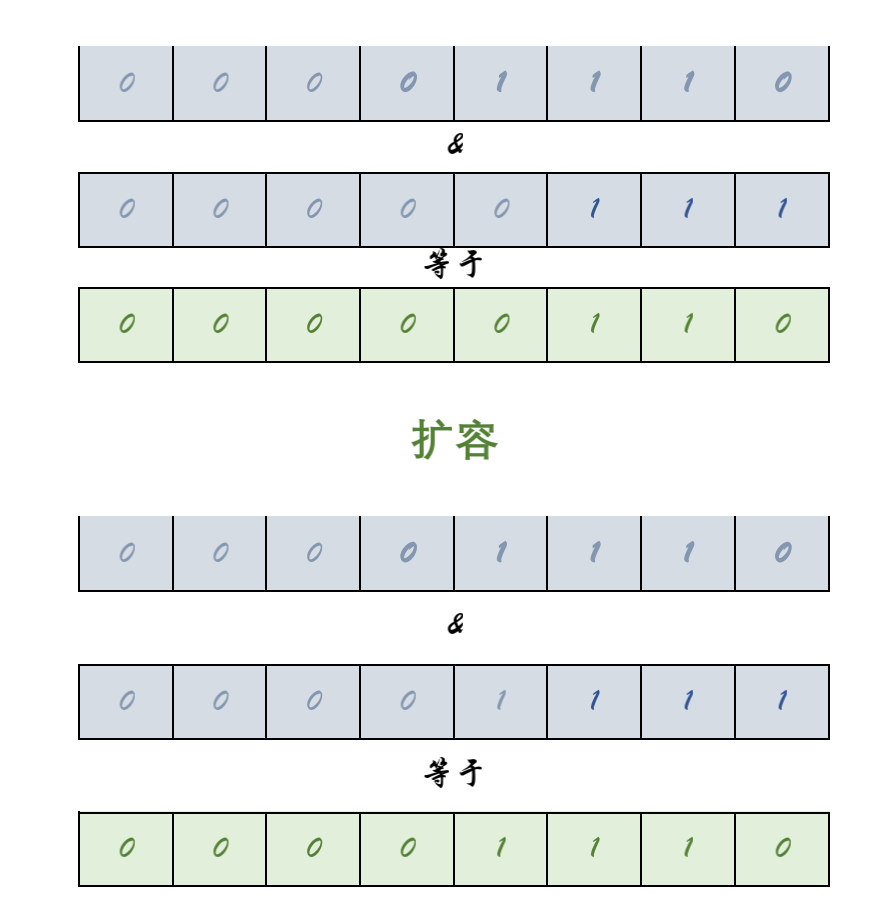
从图中我们可以看到,扩容重新计算的结果,仅仅取决于高一位的数值。如果高一位是0,那么就是在原位置,而如果是1,则加上原数组的长度。所以在数据迁移的时候只需要判断一个节点的高一位是1 or 0就可以得到他在新数组的位置,而不需要重复hash计算。HashMap把每个链表拆分成两个链表,对应原位置或原位置+原数组长度,再分别插入到新的数组中,保留原来的节点顺序,如下:
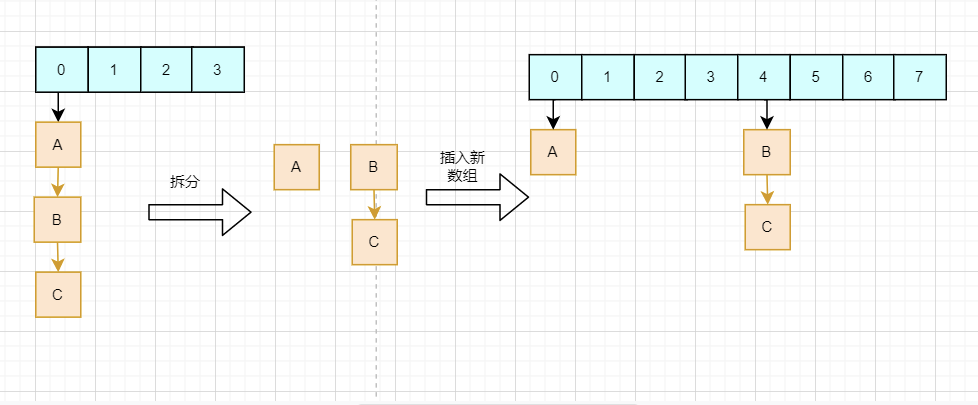
小结:
- HashMap扩容机制结合了数组长度为2的整数次幂,高效的完成数据迁移,同时能有效避免头插法造成链表环。
修改数组长度有两种情况:
- 初始值指定长度
- 扩容时候增加的空间
1:当我们初始化指定一个非2的整数次幂长度时,HashMap会调用tableSizeFor()方法:
1 | /** |
总结:通过不断移位,然后|(与)运算,最后+1的到最近的2的倍数值
2:2的倍数扩容
1 | if (oldCap > 0) { |
总结:二进制左移1位扩容
/多线程并发访问线程安全/
/
/JDK1.7 与JDK1.8 对比/